About Me
I am Max Yueqian Lin. I am a rising 2nd year PhD student in the CEI lab of the Department of Electrical and Computer Engineering at Duke University. I am fortunate to be advised by Prof. Yiran Chen and Prof. Hai “Helen” Li. I hold a Bachelor’s degree in Data Science from Duke University and Duke Kunshan University, where I graduated in May 2024 with summa cum laude honors, a signature work distinction, and served as the valedictorian. My undergraduate studies were guided by Prof. Ming Li and Prof. Kai Zhang.
My research interests are broadly in the area of multimodal large language models, with a focus on audio and vison understanding and generation.
I am currently interning at Adobe in San Jose this summer - feel free to reach out if you’d like to connect in person!
News
- [Jul. 2025] I have presented our paper SpeechPrune: Context-aware Token Pruning for Speech Information Retrieval in Nantes, France.
- [May. 2025] I am excited to join Adobe Research as a Research Intern in San Jose this summer.
[more]
- [Apr. 2025] Our paper CoreMatching: A Co-adaptive Sparse Inference Framework with Token and Neuron Pruning for Comprehensive Acceleration of Vision-Language Models has been accepted by ICML 2025. Congrats to Qinsi and the team!
- [Mar. 2025] Our paper SpeechPrune: Context-aware Token Pruning for Speech Information Retrieval has been accepted by ICME 2025. See you in Nantes, France!
- [Oct. 2024] I have reached 100 citations in Google Scholar.
- [May. 2024] I was proud to speak on behalf of my class at Duke Kunshan University’s 2024 commencement. I touched on the theme of “the three begot ten thousand things” from the Tao Te Ching, reflecting our journey from novices to graduates ready to impact the world. See news coverage here.
- [May. 2024] I visted Vienna for attending ICLR 2024. I presented our paper SD-NAE: Generating Natural Adversarial Examples with Stable Diffusion in the Tiny Papers track.
- [Mar. 2024] I am excited to announce that I will join the Department of Electrical and Computer Engineering at Duke University as a PhD student in Fall 2024.
- [Feb. 2024] A short version of our paper SD-NAE: Generating Natural Adversarial Examples with Stable Diffusion has been accepted by ICLR 2024 in the Tiny Papers track. See you in Vienna, Austria!
- [Feb. 2024] Our paper Singing Voice Data Scaling-up: An Introduction to ACE-Opencpop and KiSing-v2 has been uploaded to arXiv. We introduce two large-scale singing voice datasets, ACE-Opencpop and KiSing-v2, both of which are available for download via ESPnet.
- [Nov. 2023] We release SD-NAE, a novel method to generate Natural Adversarial Examples (NAEs) for deep image classifiers.
- [Nov. 2023] Our paper EEG-Based Speech Envelope Decoding: Structured State Space and U-Net Model Integration has been accepted by National Conference on Man-Machine Speech Communication 2023. See you in Suzhou, China!
- [Oct. 2023] I present our poster RTVis: Research Trend Visualization Toolkit in IEEE VIS 2023, which is held in Melbourne, Australia.
- [Sep. 2023] Our paper BiSinger: Bilingual Singing Voice Synthesis has been accepted by IEEE ASRU 2023.
- [Jul. 2023] Our poster RTVis: Research Trend Visualization Toolkit has been accepted by IEEE VIS 2023. See you in Melbourne, Australia!
- [Jun. 2023] We release RTVis: A real-time visualization tool for visualizing the research trend of a specific topic (GitHub).
- [Jun. 2022] Our paper about in-situ AFM tracking of nanoparticle has been published on ACM Macro Letters.
- [Jun. 2021] Our entrepreneurship project Elderly E (supported by DKU Innovation Incubator) is selected into 2021 Jiangsu Innovation and Entrepreneurship Plan for College Students (WeChat Article).
- [May. 2021] I receive the 2021 Natural and Applied Sciences Division Award from DKU (Wechat Article).
[/more]
Selected Publications
Note: * indicates equal contribution.
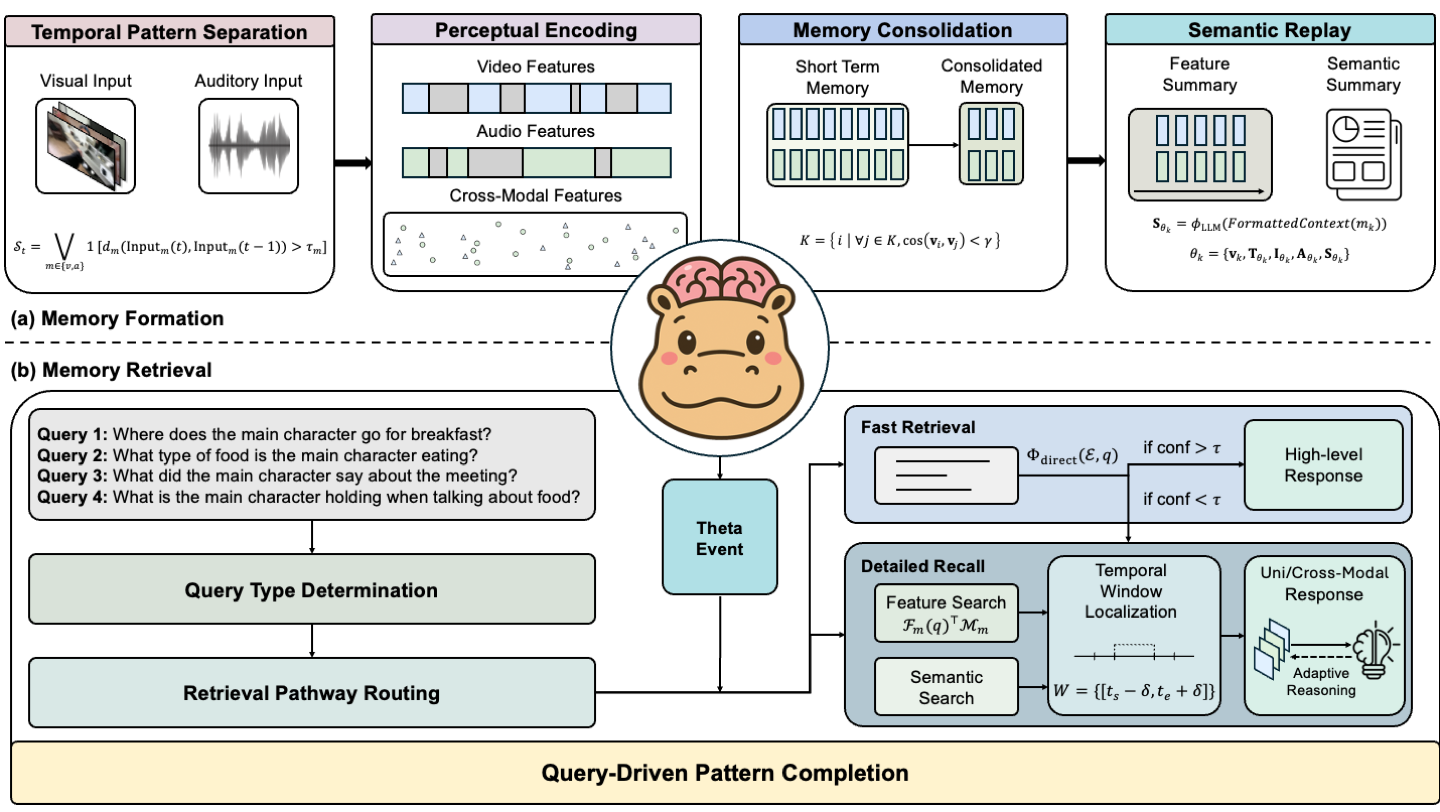
HippoMM: Hippocampal-inspired Multimodal Memory for Long Audiovisual Event Understanding
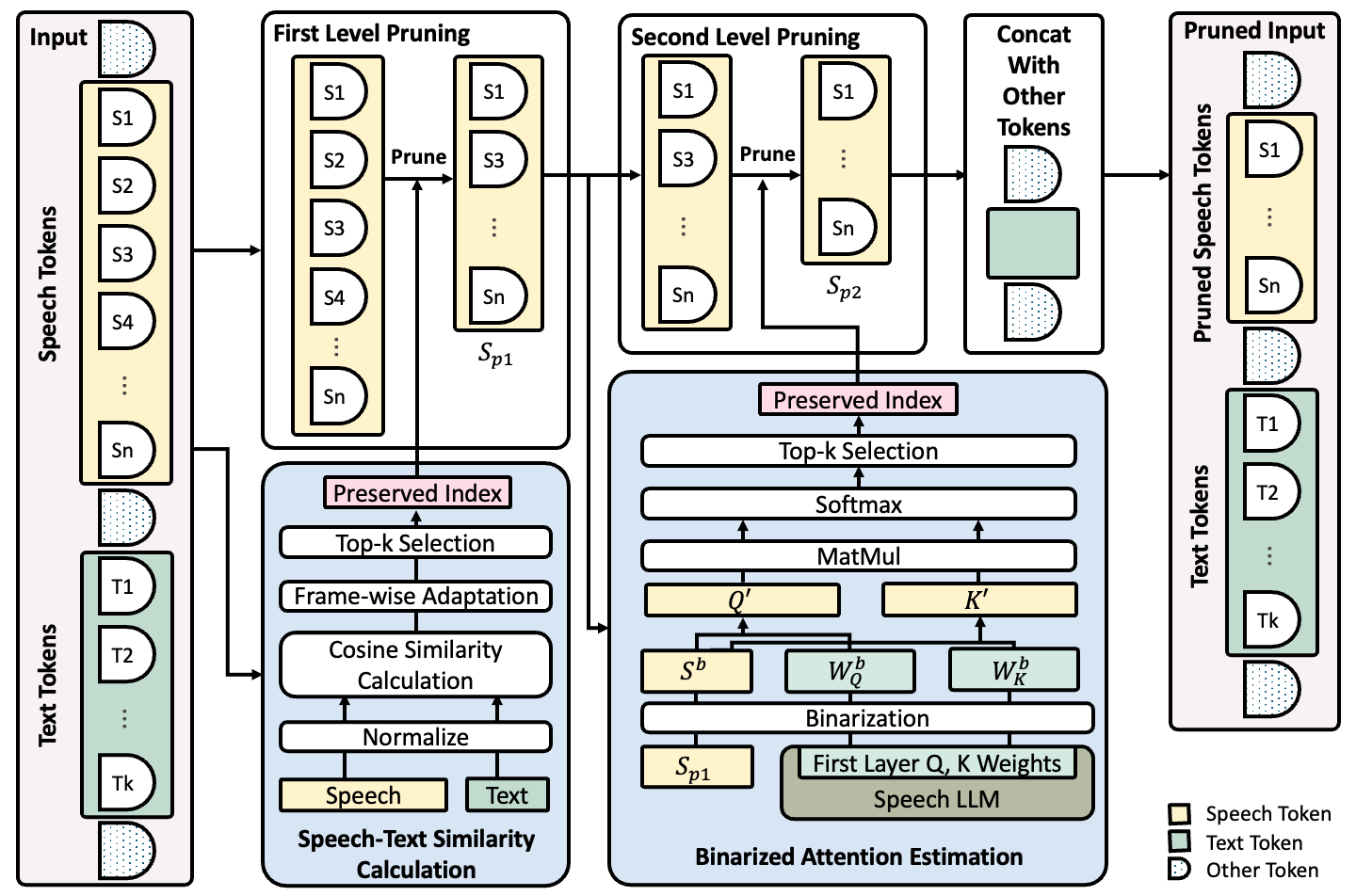
SpeechPrune: Context-aware Token Pruning for Speech Information Retrieval

Singing Voice Data Scaling-up: An Introduction to ACE-Opencpop and KiSing-v2
Jiatong Shi*,
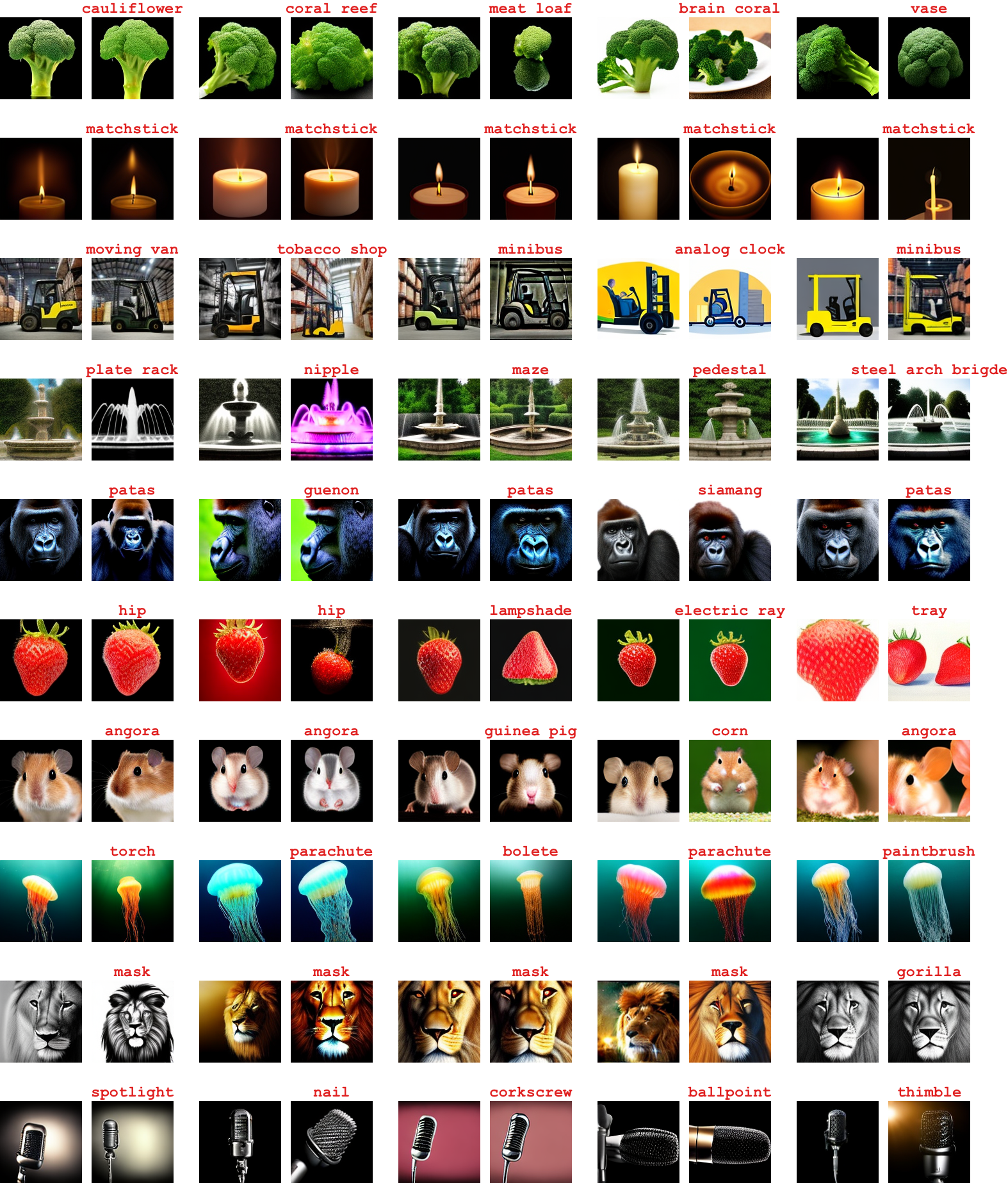
SD-NAE: Generating Natural Adversarial Examples with Stable Diffusion
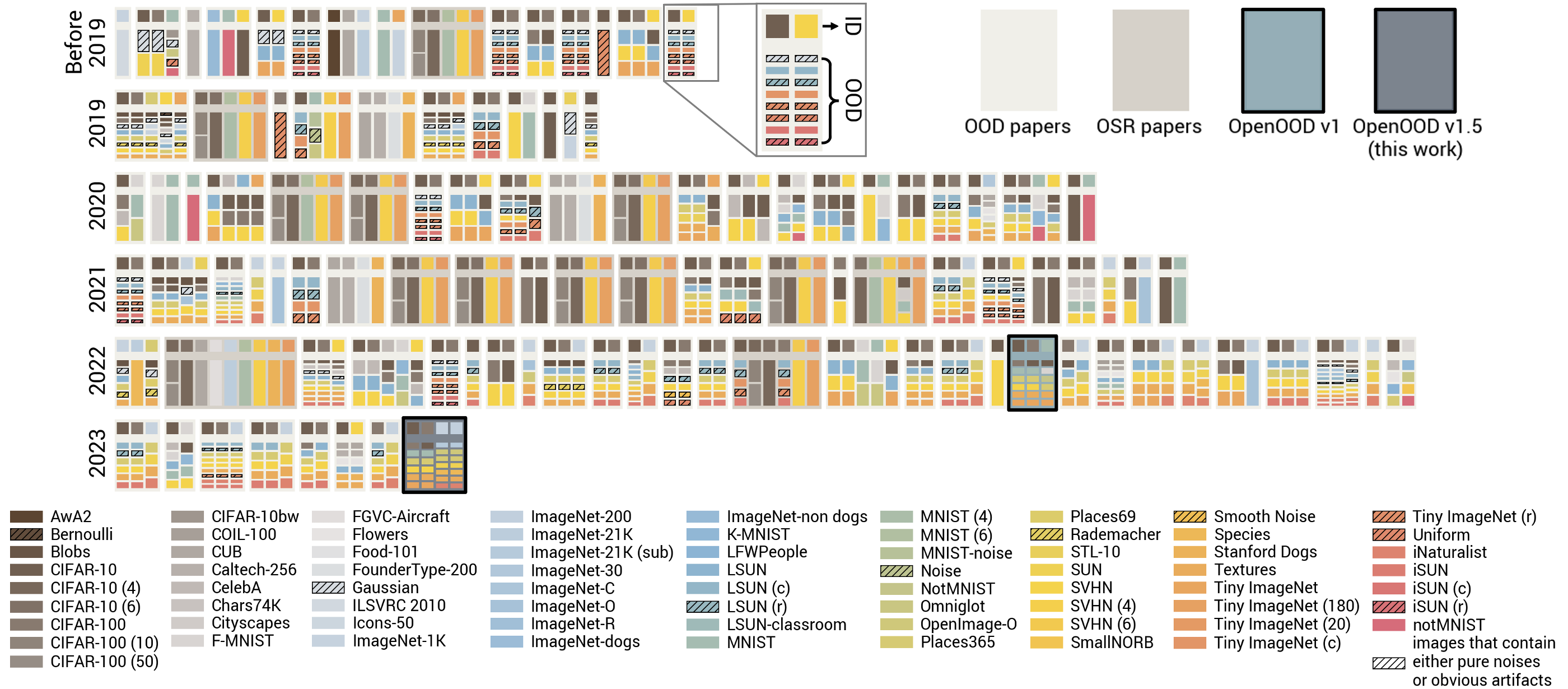
OpenOOD v1.5: Enhanced Benchmark for Out-of-Distribution Detection
Jingyang Zhang, Jingkang Yang, Pengyun Wang, Haoqi Wang,

BiSinger: Bilingual Singing Voice Synthesis
Huali Zhou*,
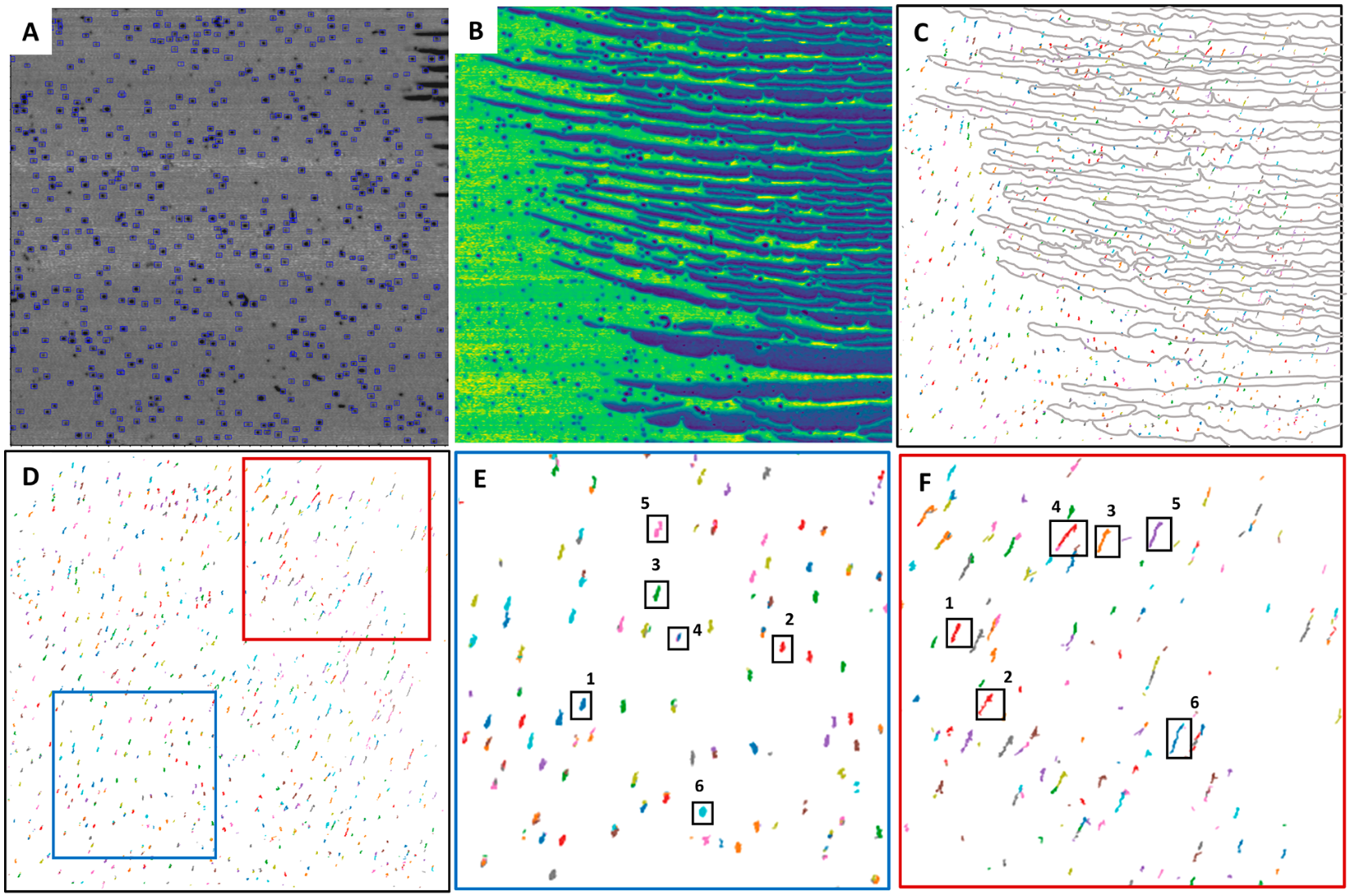
In-situ Atomic Force Microscopy Tracking of Nanoparticle Diffusion in Semicrystalline Polymers
Kamlesh Bornani, Nicholas Mendez, Abdullah S. Altorbaq, Alejandro J. Muller,